Human-in-the-loop AI for Memory Study

Problem
Rich narrative data from interviews provides deep insight into memory and cognition, but analyzing it presents a significant bottleneck. Traditionally, researchers must manually score transcripts for two distinct factors: detail type (categorizing what is being said) and accuracy (verifying if the information matches the source). Doing this manually is time-consuming and limits the study's scale.
Solution
I developed the Transcript Analyzer, an automated pipeline that leverages the GPT-4o model to process segmented interview transcripts. Each transcript is sent to the model with specific instructions to extract and classify the details into one of three buckets: Story, Background, or Character.
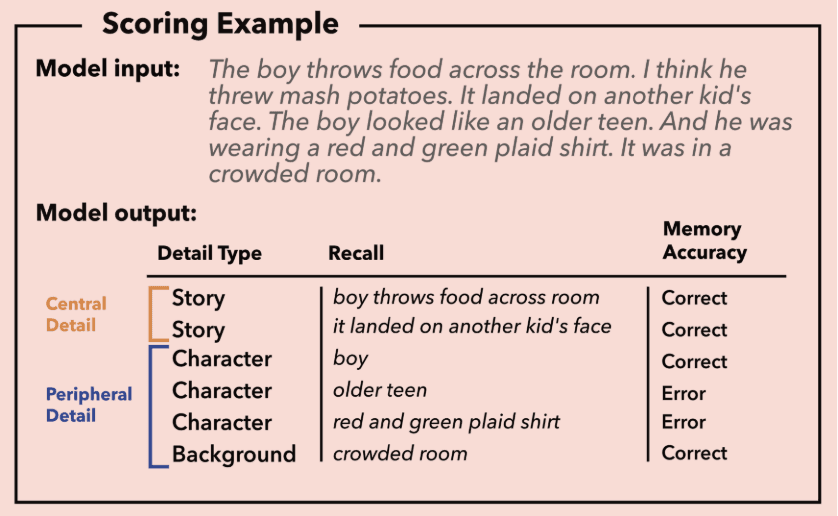
While the AI handles the categorization, human reviewers remain essential for the 'ground truth.' After the AI classifies a detail as a specific type, a human reviewer evaluates the AI’s output to score its accuracy, ensuring that the correct information is recalled from the original stimuli.
Model Performance
To evaluate how well an AI system extracts and categorizes recalled details compared to human annotation, I built a comprehensive assessment pipeline focused on structural alignment to determine whether the AI identifies a similar amount, granularity, and semantic intent of the recalled information as human researchers do. Factors include:
Granularity: whether AI extracts information at a comparable level of detail to humans
Dominant categorization: whether AI captures the primary semantic intent of recalled details
Purity and confusion patterns: how cleanly and consistently AI labels content
This framework provides a structured, interpretable assessment of the alignment between AI-generated recall representations and human cognitive annotations.
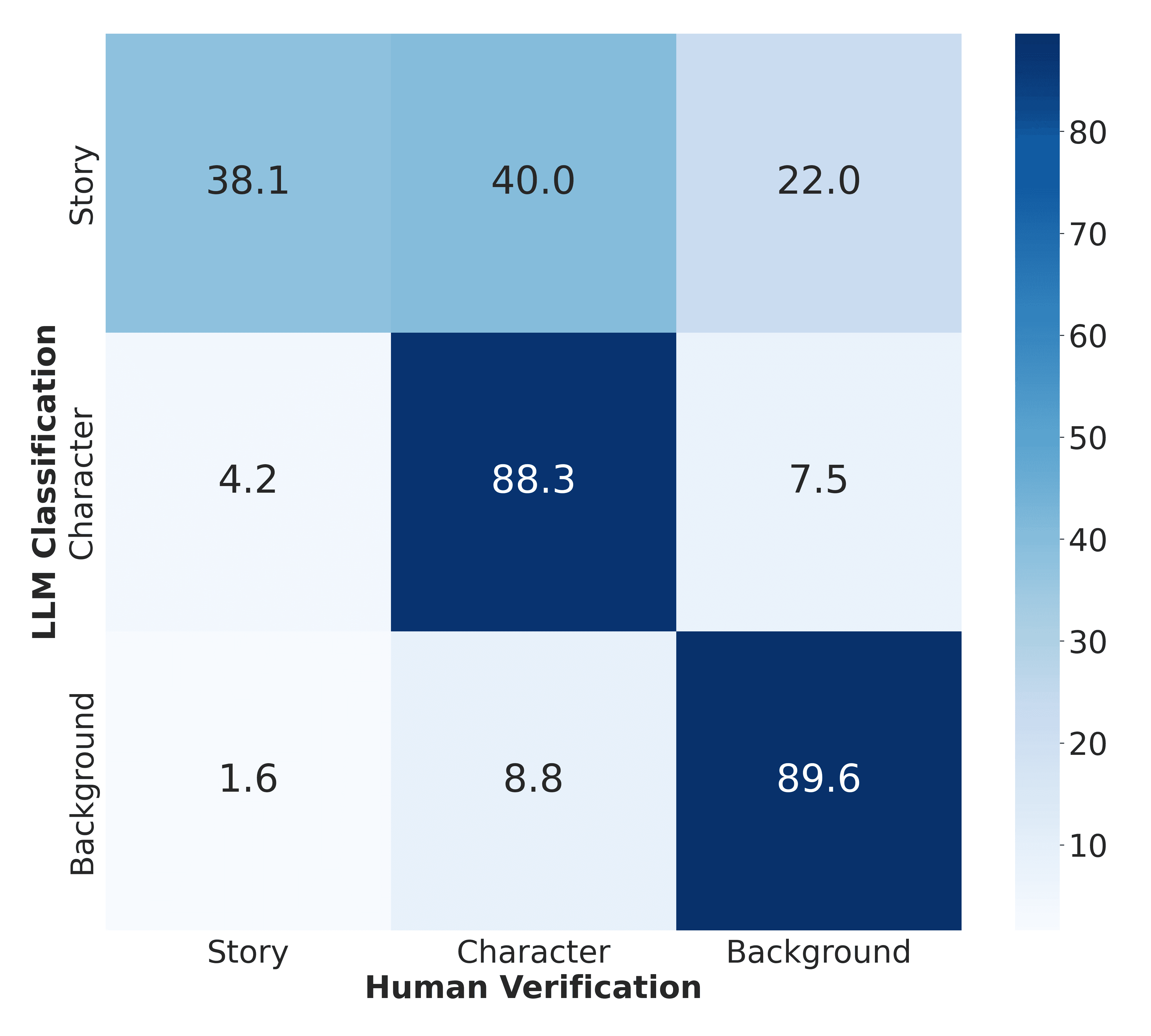
Across all evaluation metrics, the AI demonstrates strong structural alignment with human recall annotation, with two consistent characteristics:
The AI extracts higher-level details rather than human recall units.
Story-level content often includes character and background elements, which reduces the purity of the story label.
Despite these effects, the system still achieves 76% dominant-category agreement, indicating that the AI generally captures the primary semantic intent of recalled details. Overall, the AI exhibits high semantic reliability for entity and contextual information, while narrative events are represented in a more compressed and semantically mixed form.
Overall, the Transcript Analyzer successfully automates the complex task of detail categorization, allowing researchers to focus their efforts on high-level accuracy validation rather than manual labor.

