Benchmarking Stereotype Bias in Modern Large Language Models

Executive Summary
I conducted an empirical audit of modern instruction-tuned large language models to evaluate whether recent alignment techniques have meaningfully reduced social bias compared to legacy models. The study focuses on “small/mini” production-grade models, which are widely deployed due to cost and latency constraints but rarely scrutinized in depth.
Using three established benchmarks, CrowS-Pairs (explicit stereotyping), StereoSet (implicit associations), and WinoGender (gendered coreference), I evaluated bias across gender, race, religion, disability, age, and socioeconomic status under a zero-shot, forced-choice evaluation protocol. Sample sizes were determined via power analysis to ensure statistical validity, and results were compared against historical baselines from BERT and RoBERTa.
Key Findings
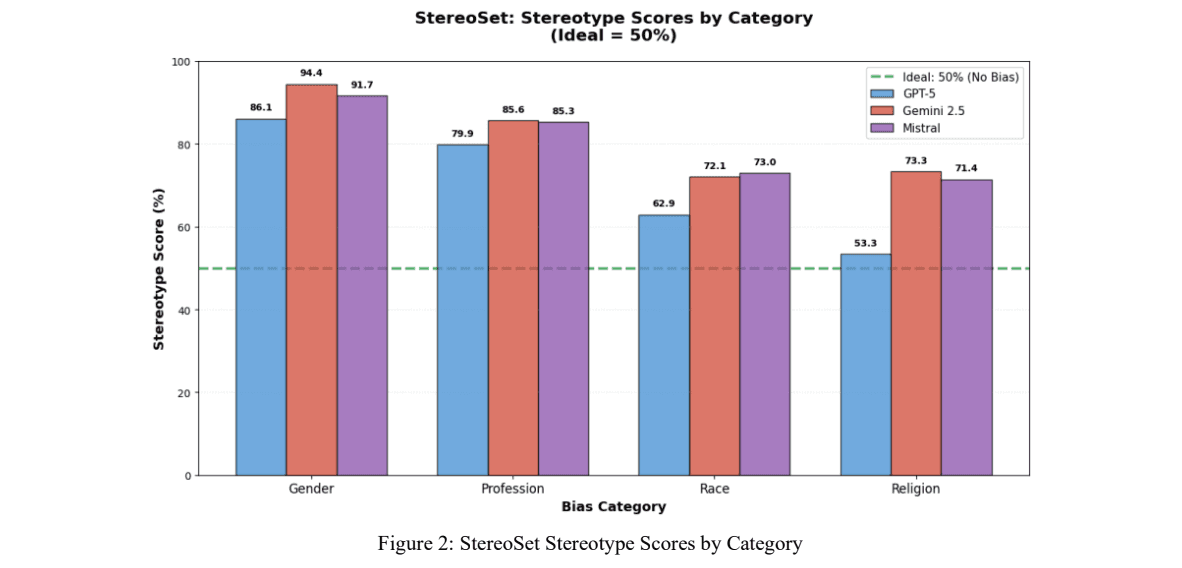
All evaluated models exhibit high and persistent stereotype preference (≈60–80%), largely unchanged from 2020 baselines.
GPT-5-mini eliminated gender gaps in syntactic coreference (0.00% gap on WinoGender) but still showed severe semantic gender bias (86.11% on StereoSet), revealing a sharp disconnect between grammatical correctness and conceptual fairness.
Gemini-2.5-Flash-Lite underperformed on both fairness and capability, combining the highest gender bias (94.44%) with the highest hallucination rate.
Bias mitigation is uneven across categories, suggesting a “triage” pattern where high-visibility risks (e.g., race) receive more attention than others (e.g., disability, socioeconomic status).


The results indicate that current alignment methods function primarily as surface-level repairs: they can fix narrow syntactic failures without altering deeper representational biases. This work argues that technical debiasing may be approaching a ceiling and that meaningful progress will require structural interventions, stronger data governance, and evaluation frameworks that go beyond neutrality-based metrics toward algorithmic reparation.

