Introduction
Within e-commerce, customer reviews are essential for guiding consumer behavior and informing business decisions. These reviews provide valuable insights into customer satisfaction, product quality, and areas for improvement. This project leverages a comprehensive dataset of women's clothing e-commerce reviews to develop predictive machine learning models. The dataset, sourced from Kaggle, contains 23,486 customer reviews alongside essential information regarding the purchases. By analyzing this rich dataset, the project aims to enhance the understanding of customer preferences and improve product recommendations.
Problem Statement
The primary objective of this project is to develop predictive machine learning models for two classification tasks:
Recommendation Prediction: Predict whether a user recommends a product. This is a binary classification task where the target variable is "Recommended IND" (1 for recommended, 0 for not recommended).
Star Rating Prediction: Predict the user's given star rating (1 to 5 stars) for the items. This task involves ordinal classification, where the model must accurately predict the specific star rating assigned by the customer.
The insights from this project can help to improve customer satisfaction, enhance product recommendations, and ultimately drive better customer engagement and sales for e-commerce businesses.


Methodologies
The process begins with fundamental data preparation techniques optimized for natural language processing of customers’ reviews. Subsequently, the strategy employs a comprehensive text classification pipeline to transform unstructured review data into structured features suitable for machine learning. Multiple models, including Logistic Regression, Random Forest, XGBoost, and LightGBM, are evaluated. The approach balances computational efficiency and predictive accuracy, leveraging advanced techniques to address the subtleties of clothing reviews.
The key feature in this dataset is customers’ reviews; thus, the strategy for task 1 encompasses a text classification pipeline, including:
Sentiment Analysis: Using VADER to extract sentiment scores (positive, negative, neutral, compound) which quantifies the emotional tone of review titles and text.
Basic Text Statistics: Adding text length and word count as features, which can indicate review thoroughness/detail.
BERT Embeddings: Converting text into rich semantic vectors that capture contextual meaning and nuance.
This approach transforms unstructured text data into structured features while preserving semantic meaning, captures multiple dimensions of the review titles and text (sentiment, length, semantic content), and prepares the data in a format ready for machine learning algorithms. BERT embeddings are suitable for this challenge because clothing reviews often contain subtle language about fit, quality, and style that simpler bag-of-words approaches might miss, while sentiment analysis directly captures customer satisfaction signals.
def get_sentiment(text):
vader = SentimentIntensityAnalyzer()
sentiment = vader.polarity_scores(text)
return sentiment["pos"], sentiment["neu"], sentiment["neg"], sentiment["compound"]
train_data[["Sent_Pos_Review", "Sent_Neu_Review", "Sent_Neg_Review", "Sent_Compound_Review"]] = train_data["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data[["Sent_Pos_Title", "Sent_Neu_Title", "Sent_Neg_Title", "Sent_Compound_Title"]] = train_data["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data[["Sent_Pos_Review", "Sent_Neu_Review", "Sent_Neg_Review", "Sent_Compound_Review"]] = test_data["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data[["Sent_Pos_Title", "Sent_Neu_Title", "Sent_Neg_Title", "Sent_Compound_Title"]] = test_data["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data["Review_Length"] = train_data["Review Text Cleaned"].apply(lambda x: len(str(x)))
train_data["Word_Count_Review"] = train_data["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
train_data["Title_Length"] = train_data["Title Cleaned"].apply(lambda x: len(str(x)))
train_data["Word_Count_Title"] = train_data["Title Cleaned"].apply(lambda x: len(str(x).split()))
test_data["Review_Length"] = test_data["Review Text Cleaned"].apply(lambda x: len(str(x)))
test_data["Word_Count_Review"] = test_data["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
test_data["Title_Length"] = test_data["Title Cleaned"].apply(lambda x: len(str(x)))
test_data["Word_Count_Title"] = test_data["Title Cleaned"].apply(lambda x: len(str(x).split()))
train_features = train_data.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned", "Rating"])
test_features = test_data.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned", "Rating"])
model = SentenceTransformer('all-MiniLM-L6-v2')
train_review_embeddings = model.encode(train_data["Review Text Cleaned"].tolist())
train_title_embeddings = model.encode(train_data["Title Cleaned"].tolist())
test_review_embeddings = model.encode(test_data["Review Text Cleaned"].tolist())
test_title_embeddings = model.encode(test_data["Title Cleaned"].tolist())
embed_dim = train_review_embeddings.shape[1]
review_embed_cols = [f'review_embed_{i}' for i in range(embed_dim)]
title_embed_cols = [f'title_embed_{i}' for i in range(embed_dim)]
X_train_review_bert = pd.DataFrame(train_review_embeddings, columns=review_embed_cols)
X_train_title_bert = pd.DataFrame(train_title_embeddings, columns=title_embed_cols)
X_test_review_bert = pd.DataFrame(test_review_embeddings, columns=review_embed_cols)
X_test_title_bert = pd.DataFrame(test_title_embeddings, columns=title_embed_cols)
train_features_reset = train_features.reset_index(drop=True)
test_features_reset = test_features.reset_index(drop=True)
X_train_review_bert_reset = X_train_review_bert.reset_index(drop=True)
X_train_title_bert_reset = X_train_title_bert.reset_index(drop=True)
X_test_review_bert_reset = X_test_review_bert.reset_index(drop=True)
X_test_title_bert_reset = X_test_title_bert.reset_index(drop=True)
X_train_final = pd.concat([train_features_reset, X_train_review_bert_reset, X_train_title_bert_reset], axis=1)
X_test_final = pd.concat([test_features_reset, X_test_review_bert_reset, X_test_title_bert_reset], axis=1)
print(f"X_train_final shape: {X_train_final.shape}")
print(f"X_test_final shape: {X_test_final.shape}")
def get_sentiment(text):
vader = SentimentIntensityAnalyzer()
sentiment = vader.polarity_scores(text)
return sentiment["pos"], sentiment["neu"], sentiment["neg"], sentiment["compound"]
train_data[["Sent_Pos_Review", "Sent_Neu_Review", "Sent_Neg_Review", "Sent_Compound_Review"]] = train_data["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data[["Sent_Pos_Title", "Sent_Neu_Title", "Sent_Neg_Title", "Sent_Compound_Title"]] = train_data["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data[["Sent_Pos_Review", "Sent_Neu_Review", "Sent_Neg_Review", "Sent_Compound_Review"]] = test_data["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data[["Sent_Pos_Title", "Sent_Neu_Title", "Sent_Neg_Title", "Sent_Compound_Title"]] = test_data["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data["Review_Length"] = train_data["Review Text Cleaned"].apply(lambda x: len(str(x)))
train_data["Word_Count_Review"] = train_data["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
train_data["Title_Length"] = train_data["Title Cleaned"].apply(lambda x: len(str(x)))
train_data["Word_Count_Title"] = train_data["Title Cleaned"].apply(lambda x: len(str(x).split()))
test_data["Review_Length"] = test_data["Review Text Cleaned"].apply(lambda x: len(str(x)))
test_data["Word_Count_Review"] = test_data["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
test_data["Title_Length"] = test_data["Title Cleaned"].apply(lambda x: len(str(x)))
test_data["Word_Count_Title"] = test_data["Title Cleaned"].apply(lambda x: len(str(x).split()))
train_features = train_data.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned", "Rating"])
test_features = test_data.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned", "Rating"])
model = SentenceTransformer('all-MiniLM-L6-v2')
train_review_embeddings = model.encode(train_data["Review Text Cleaned"].tolist())
train_title_embeddings = model.encode(train_data["Title Cleaned"].tolist())
test_review_embeddings = model.encode(test_data["Review Text Cleaned"].tolist())
test_title_embeddings = model.encode(test_data["Title Cleaned"].tolist())
embed_dim = train_review_embeddings.shape[1]
review_embed_cols = [f'review_embed_{i}' for i in range(embed_dim)]
title_embed_cols = [f'title_embed_{i}' for i in range(embed_dim)]
X_train_review_bert = pd.DataFrame(train_review_embeddings, columns=review_embed_cols)
X_train_title_bert = pd.DataFrame(train_title_embeddings, columns=title_embed_cols)
X_test_review_bert = pd.DataFrame(test_review_embeddings, columns=review_embed_cols)
X_test_title_bert = pd.DataFrame(test_title_embeddings, columns=title_embed_cols)
train_features_reset = train_features.reset_index(drop=True)
test_features_reset = test_features.reset_index(drop=True)
X_train_review_bert_reset = X_train_review_bert.reset_index(drop=True)
X_train_title_bert_reset = X_train_title_bert.reset_index(drop=True)
X_test_review_bert_reset = X_test_review_bert.reset_index(drop=True)
X_test_title_bert_reset = X_test_title_bert.reset_index(drop=True)
X_train_final = pd.concat([train_features_reset, X_train_review_bert_reset, X_train_title_bert_reset], axis=1)
X_test_final = pd.concat([test_features_reset, X_test_review_bert_reset, X_test_title_bert_reset], axis=1)
print(f"X_train_final shape: {X_train_final.shape}")
print(f"X_test_final shape: {X_test_final.shape}")
def get_sentiment(text):
vader = SentimentIntensityAnalyzer()
sentiment = vader.polarity_scores(text)
return sentiment["pos"], sentiment["neu"], sentiment["neg"], sentiment["compound"]
train_data[["Sent_Pos_Review", "Sent_Neu_Review", "Sent_Neg_Review", "Sent_Compound_Review"]] = train_data["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data[["Sent_Pos_Title", "Sent_Neu_Title", "Sent_Neg_Title", "Sent_Compound_Title"]] = train_data["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data[["Sent_Pos_Review", "Sent_Neu_Review", "Sent_Neg_Review", "Sent_Compound_Review"]] = test_data["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data[["Sent_Pos_Title", "Sent_Neu_Title", "Sent_Neg_Title", "Sent_Compound_Title"]] = test_data["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data["Review_Length"] = train_data["Review Text Cleaned"].apply(lambda x: len(str(x)))
train_data["Word_Count_Review"] = train_data["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
train_data["Title_Length"] = train_data["Title Cleaned"].apply(lambda x: len(str(x)))
train_data["Word_Count_Title"] = train_data["Title Cleaned"].apply(lambda x: len(str(x).split()))
test_data["Review_Length"] = test_data["Review Text Cleaned"].apply(lambda x: len(str(x)))
test_data["Word_Count_Review"] = test_data["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
test_data["Title_Length"] = test_data["Title Cleaned"].apply(lambda x: len(str(x)))
test_data["Word_Count_Title"] = test_data["Title Cleaned"].apply(lambda x: len(str(x).split()))
train_features = train_data.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned", "Rating"])
test_features = test_data.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned", "Rating"])
model = SentenceTransformer('all-MiniLM-L6-v2')
train_review_embeddings = model.encode(train_data["Review Text Cleaned"].tolist())
train_title_embeddings = model.encode(train_data["Title Cleaned"].tolist())
test_review_embeddings = model.encode(test_data["Review Text Cleaned"].tolist())
test_title_embeddings = model.encode(test_data["Title Cleaned"].tolist())
embed_dim = train_review_embeddings.shape[1]
review_embed_cols = [f'review_embed_{i}' for i in range(embed_dim)]
title_embed_cols = [f'title_embed_{i}' for i in range(embed_dim)]
X_train_review_bert = pd.DataFrame(train_review_embeddings, columns=review_embed_cols)
X_train_title_bert = pd.DataFrame(train_title_embeddings, columns=title_embed_cols)
X_test_review_bert = pd.DataFrame(test_review_embeddings, columns=review_embed_cols)
X_test_title_bert = pd.DataFrame(test_title_embeddings, columns=title_embed_cols)
train_features_reset = train_features.reset_index(drop=True)
test_features_reset = test_features.reset_index(drop=True)
X_train_review_bert_reset = X_train_review_bert.reset_index(drop=True)
X_train_title_bert_reset = X_train_title_bert.reset_index(drop=True)
X_test_review_bert_reset = X_test_review_bert.reset_index(drop=True)
X_test_title_bert_reset = X_test_title_bert.reset_index(drop=True)
X_train_final = pd.concat([train_features_reset, X_train_review_bert_reset, X_train_title_bert_reset], axis=1)
X_test_final = pd.concat([test_features_reset, X_test_review_bert_reset, X_test_title_bert_reset], axis=1)
print(f"X_train_final shape: {X_train_final.shape}")
print(f"X_test_final shape: {X_test_final.shape}")
def get_sentiment(text):
vader = SentimentIntensityAnalyzer()
sentiment = vader.polarity_scores(text)
return sentiment["pos"], sentiment["neu"], sentiment["neg"], sentiment["compound"]
train_data[["Sent_Pos_Review", "Sent_Neu_Review", "Sent_Neg_Review", "Sent_Compound_Review"]] = train_data["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data[["Sent_Pos_Title", "Sent_Neu_Title", "Sent_Neg_Title", "Sent_Compound_Title"]] = train_data["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data[["Sent_Pos_Review", "Sent_Neu_Review", "Sent_Neg_Review", "Sent_Compound_Review"]] = test_data["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data[["Sent_Pos_Title", "Sent_Neu_Title", "Sent_Neg_Title", "Sent_Compound_Title"]] = test_data["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data["Review_Length"] = train_data["Review Text Cleaned"].apply(lambda x: len(str(x)))
train_data["Word_Count_Review"] = train_data["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
train_data["Title_Length"] = train_data["Title Cleaned"].apply(lambda x: len(str(x)))
train_data["Word_Count_Title"] = train_data["Title Cleaned"].apply(lambda x: len(str(x).split()))
test_data["Review_Length"] = test_data["Review Text Cleaned"].apply(lambda x: len(str(x)))
test_data["Word_Count_Review"] = test_data["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
test_data["Title_Length"] = test_data["Title Cleaned"].apply(lambda x: len(str(x)))
test_data["Word_Count_Title"] = test_data["Title Cleaned"].apply(lambda x: len(str(x).split()))
train_features = train_data.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned", "Rating"])
test_features = test_data.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned", "Rating"])
model = SentenceTransformer('all-MiniLM-L6-v2')
train_review_embeddings = model.encode(train_data["Review Text Cleaned"].tolist())
train_title_embeddings = model.encode(train_data["Title Cleaned"].tolist())
test_review_embeddings = model.encode(test_data["Review Text Cleaned"].tolist())
test_title_embeddings = model.encode(test_data["Title Cleaned"].tolist())
embed_dim = train_review_embeddings.shape[1]
review_embed_cols = [f'review_embed_{i}' for i in range(embed_dim)]
title_embed_cols = [f'title_embed_{i}' for i in range(embed_dim)]
X_train_review_bert = pd.DataFrame(train_review_embeddings, columns=review_embed_cols)
X_train_title_bert = pd.DataFrame(train_title_embeddings, columns=title_embed_cols)
X_test_review_bert = pd.DataFrame(test_review_embeddings, columns=review_embed_cols)
X_test_title_bert = pd.DataFrame(test_title_embeddings, columns=title_embed_cols)
train_features_reset = train_features.reset_index(drop=True)
test_features_reset = test_features.reset_index(drop=True)
X_train_review_bert_reset = X_train_review_bert.reset_index(drop=True)
X_train_title_bert_reset = X_train_title_bert.reset_index(drop=True)
X_test_review_bert_reset = X_test_review_bert.reset_index(drop=True)
X_test_title_bert_reset = X_test_title_bert.reset_index(drop=True)
X_train_final = pd.concat([train_features_reset, X_train_review_bert_reset, X_train_title_bert_reset], axis=1)
X_test_final = pd.concat([test_features_reset, X_test_review_bert_reset, X_test_title_bert_reset], axis=1)
print(f"X_train_final shape: {X_train_final.shape}")
print(f"X_test_final shape: {X_test_final.shape}")For task 2, the approach is adjusted slightly as there are fewer features involved. This task only uses review title and text. Accordingly, a comprehensive text processing pipeline is applied:
Sentiment Analysis: Using TextBlob to map the polarity to negative, neutral, and positive categories.
TF-IDF Vectorization: Considering bigrams and 4-grams, the cleaned 'Review Text' is converted into numerical features
Sentiment Intensity Calculation: The program uses VADER to calculate sentiment intensity scores for the cleaned 'Review Text' and 'Title' columns.
Emotion Score Extraction with Feature Engineering: First, NRCLex is used to calculate emotion scores for the cleaned 'Review Text' and 'Title' columns. Afterward, the program expands the emotion scores into separate columns for each emotion.
These steps collectively help in creating a robust feature set that can effectively capture the nuances in review data, such as the reviewer's feelings, making it suitable for predicting ratings accurately.
def get_sentiment(text):
blob = TextBlob(text)
polarity = blob.sentiment.polarity
if polarity < -0.05:
return 1, 0, 0
elif polarity > 0.05:
return 0, 0, 1
else:
return 0, 1, 0
train_data_task2[["Sent_Neg_Review", "Sent_Neu_Review", "Sent_Pos_Review"]] = train_data_task2["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data_task2[["Sent_Neg_Title", "Sent_Neu_Title", "Sent_Pos_Title"]] = train_data_task2["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data_task2[["Sent_Neg_Review", "Sent_Neu_Review", "Sent_Pos_Review"]] = test_data_task2["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data_task2[["Sent_Neg_Title", "Sent_Neu_Title", "Sent_Pos_Title"]] = test_data_task2["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data_task2["Review_Length"] = train_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x)))
train_data_task2["Word_Count_Review"] = train_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
train_data_task2["Title_Length"] = train_data_task2["Title Cleaned"].apply(lambda x: len(str(x)))
train_data_task2["Word_Count_Title"] = train_data_task2["Title Cleaned"].apply(lambda x: len(str(x).split()))
test_data_task2["Review_Length"] = test_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x)))
test_data_task2["Word_Count_Review"] = test_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
test_data_task2["Title_Length"] = test_data_task2["Title Cleaned"].apply(lambda x: len(str(x)))
test_data_task2["Word_Count_Title"] = test_data_task2["Title Cleaned"].apply(lambda x: len(str(x).split()))
tfidf_review = TfidfVectorizer(ngram_range=(2, 4), max_features=100)
train_review_tfidf = tfidf_review.fit_transform(train_data_task2["Review Text Cleaned"])
test_review_tfidf = tfidf_review.transform(test_data_task2["Review Text Cleaned"])
train_review_tfidf_df = pd.DataFrame(train_review_tfidf.toarray(), columns=[f"review_tfidf_{i}" for i in range(train_review_tfidf.shape[1])])
test_review_tfidf_df = pd.DataFrame(test_review_tfidf.toarray(), columns=[f"review_tfidf_{i}" for i in range(test_review_tfidf.shape[1])])
vader = SentimentIntensityAnalyzer()
def get_sentiment_intensity(text):
sentiment = vader.polarity_scores(text)
return sentiment["compound"]
train_data_task2["Sentiment_Intensity_Review"] = train_data_task2["Review Text Cleaned"].apply(get_sentiment_intensity)
train_data_task2["Sentiment_Intensity_Title"] = train_data_task2["Title Cleaned"].apply(get_sentiment_intensity)
test_data_task2["Sentiment_Intensity_Review"] = test_data_task2["Review Text Cleaned"].apply(get_sentiment_intensity)
test_data_task2["Sentiment_Intensity_Title"] = test_data_task2["Title Cleaned"].apply(get_sentiment_intensity)
def get_emotion_scores_nrclex(text):
emotion = NRCLex(text)
return emotion.affect_frequencies
train_data_task2["Emotion_Scores_Review"] = train_data_task2["Review Text Cleaned"].apply(get_emotion_scores_nrclex)
train_data_task2["Emotion_Scores_Title"] = train_data_task2["Title Cleaned"].apply(get_emotion_scores_nrclex)
test_data_task2["Emotion_Scores_Review"] = test_data_task2["Review Text Cleaned"].apply(get_emotion_scores_nrclex)
test_data_task2["Emotion_Scores_Title"] = test_data_task2["Title Cleaned"].apply(get_emotion_scores_nrclex)
emotions = ["anger", "anticipation", "disgust", "fear", "joy", "sadness", "surprise", "trust"]
def expand_emotion_scores(df, column_prefix):
for emotion in emotions:
df[f"{column_prefix}_{emotion}"] = df[column_prefix].apply(lambda x: x.get(emotion, 0))
return df.drop(columns=[column_prefix])
train_features_2 = train_data_task2.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned"])
test_features_2 = test_data_task2.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned"])
train_features_2_reset = train_features_2.reset_index(drop=True)
test_features_2_reset = test_features_2.reset_index(drop=True)
X_train_task2 = train_features_2_reset
X_test_task2 = test_features_2_reset
X_train_task2 = pd.concat([X_train_task2, train_review_tfidf_df], axis=1)
X_test_task2 = pd.concat([X_test_task2, test_review_tfidf_df], axis=1)
X_train_task2["Sentiment_Intensity_Review"] = train_data_task2["Sentiment_Intensity_Review"]
X_train_task2["Sentiment_Intensity_Title"] = train_data_task2["Sentiment_Intensity_Title"]
X_test_task2["Sentiment_Intensity_Review"] = test_data_task2["Sentiment_Intensity_Review"]
X_test_task2["Sentiment_Intensity_Title"] = test_data_task2["Sentiment_Intensity_Title"]
X_train_task2["Emotion_Scores_Review"] = train_data_task2["Emotion_Scores_Review"]
X_train_task2["Emotion_Scores_Title"] = train_data_task2["Emotion_Scores_Title"]
X_test_task2["Emotion_Scores_Review"] = test_data_task2["Emotion_Scores_Review"]
X_test_task2["Emotion_Scores_Title"] = test_data_task2["Emotion_Scores_Title"]
X_train_task2 = expand_emotion_scores(X_train_task2, "Emotion_Scores_Review")
X_train_task2 = expand_emotion_scores(X_train_task2, "Emotion_Scores_Title")
X_test_task2 = expand_emotion_scores(X_test_task2, "Emotion_Scores_Review")
X_test_task2 = expand_emotion_scores(X_test_task2, "Emotion_Scores_Title")
print("X_train_task2 shape:", X_train_task2.shape)
print("X_test_task2 shape:", X_test_task2.shape)
def get_sentiment(text):
blob = TextBlob(text)
polarity = blob.sentiment.polarity
if polarity < -0.05:
return 1, 0, 0
elif polarity > 0.05:
return 0, 0, 1
else:
return 0, 1, 0
train_data_task2[["Sent_Neg_Review", "Sent_Neu_Review", "Sent_Pos_Review"]] = train_data_task2["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data_task2[["Sent_Neg_Title", "Sent_Neu_Title", "Sent_Pos_Title"]] = train_data_task2["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data_task2[["Sent_Neg_Review", "Sent_Neu_Review", "Sent_Pos_Review"]] = test_data_task2["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data_task2[["Sent_Neg_Title", "Sent_Neu_Title", "Sent_Pos_Title"]] = test_data_task2["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data_task2["Review_Length"] = train_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x)))
train_data_task2["Word_Count_Review"] = train_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
train_data_task2["Title_Length"] = train_data_task2["Title Cleaned"].apply(lambda x: len(str(x)))
train_data_task2["Word_Count_Title"] = train_data_task2["Title Cleaned"].apply(lambda x: len(str(x).split()))
test_data_task2["Review_Length"] = test_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x)))
test_data_task2["Word_Count_Review"] = test_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
test_data_task2["Title_Length"] = test_data_task2["Title Cleaned"].apply(lambda x: len(str(x)))
test_data_task2["Word_Count_Title"] = test_data_task2["Title Cleaned"].apply(lambda x: len(str(x).split()))
tfidf_review = TfidfVectorizer(ngram_range=(2, 4), max_features=100)
train_review_tfidf = tfidf_review.fit_transform(train_data_task2["Review Text Cleaned"])
test_review_tfidf = tfidf_review.transform(test_data_task2["Review Text Cleaned"])
train_review_tfidf_df = pd.DataFrame(train_review_tfidf.toarray(), columns=[f"review_tfidf_{i}" for i in range(train_review_tfidf.shape[1])])
test_review_tfidf_df = pd.DataFrame(test_review_tfidf.toarray(), columns=[f"review_tfidf_{i}" for i in range(test_review_tfidf.shape[1])])
vader = SentimentIntensityAnalyzer()
def get_sentiment_intensity(text):
sentiment = vader.polarity_scores(text)
return sentiment["compound"]
train_data_task2["Sentiment_Intensity_Review"] = train_data_task2["Review Text Cleaned"].apply(get_sentiment_intensity)
train_data_task2["Sentiment_Intensity_Title"] = train_data_task2["Title Cleaned"].apply(get_sentiment_intensity)
test_data_task2["Sentiment_Intensity_Review"] = test_data_task2["Review Text Cleaned"].apply(get_sentiment_intensity)
test_data_task2["Sentiment_Intensity_Title"] = test_data_task2["Title Cleaned"].apply(get_sentiment_intensity)
def get_emotion_scores_nrclex(text):
emotion = NRCLex(text)
return emotion.affect_frequencies
train_data_task2["Emotion_Scores_Review"] = train_data_task2["Review Text Cleaned"].apply(get_emotion_scores_nrclex)
train_data_task2["Emotion_Scores_Title"] = train_data_task2["Title Cleaned"].apply(get_emotion_scores_nrclex)
test_data_task2["Emotion_Scores_Review"] = test_data_task2["Review Text Cleaned"].apply(get_emotion_scores_nrclex)
test_data_task2["Emotion_Scores_Title"] = test_data_task2["Title Cleaned"].apply(get_emotion_scores_nrclex)
emotions = ["anger", "anticipation", "disgust", "fear", "joy", "sadness", "surprise", "trust"]
def expand_emotion_scores(df, column_prefix):
for emotion in emotions:
df[f"{column_prefix}_{emotion}"] = df[column_prefix].apply(lambda x: x.get(emotion, 0))
return df.drop(columns=[column_prefix])
train_features_2 = train_data_task2.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned"])
test_features_2 = test_data_task2.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned"])
train_features_2_reset = train_features_2.reset_index(drop=True)
test_features_2_reset = test_features_2.reset_index(drop=True)
X_train_task2 = train_features_2_reset
X_test_task2 = test_features_2_reset
X_train_task2 = pd.concat([X_train_task2, train_review_tfidf_df], axis=1)
X_test_task2 = pd.concat([X_test_task2, test_review_tfidf_df], axis=1)
X_train_task2["Sentiment_Intensity_Review"] = train_data_task2["Sentiment_Intensity_Review"]
X_train_task2["Sentiment_Intensity_Title"] = train_data_task2["Sentiment_Intensity_Title"]
X_test_task2["Sentiment_Intensity_Review"] = test_data_task2["Sentiment_Intensity_Review"]
X_test_task2["Sentiment_Intensity_Title"] = test_data_task2["Sentiment_Intensity_Title"]
X_train_task2["Emotion_Scores_Review"] = train_data_task2["Emotion_Scores_Review"]
X_train_task2["Emotion_Scores_Title"] = train_data_task2["Emotion_Scores_Title"]
X_test_task2["Emotion_Scores_Review"] = test_data_task2["Emotion_Scores_Review"]
X_test_task2["Emotion_Scores_Title"] = test_data_task2["Emotion_Scores_Title"]
X_train_task2 = expand_emotion_scores(X_train_task2, "Emotion_Scores_Review")
X_train_task2 = expand_emotion_scores(X_train_task2, "Emotion_Scores_Title")
X_test_task2 = expand_emotion_scores(X_test_task2, "Emotion_Scores_Review")
X_test_task2 = expand_emotion_scores(X_test_task2, "Emotion_Scores_Title")
print("X_train_task2 shape:", X_train_task2.shape)
print("X_test_task2 shape:", X_test_task2.shape)
def get_sentiment(text):
blob = TextBlob(text)
polarity = blob.sentiment.polarity
if polarity < -0.05:
return 1, 0, 0
elif polarity > 0.05:
return 0, 0, 1
else:
return 0, 1, 0
train_data_task2[["Sent_Neg_Review", "Sent_Neu_Review", "Sent_Pos_Review"]] = train_data_task2["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data_task2[["Sent_Neg_Title", "Sent_Neu_Title", "Sent_Pos_Title"]] = train_data_task2["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data_task2[["Sent_Neg_Review", "Sent_Neu_Review", "Sent_Pos_Review"]] = test_data_task2["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data_task2[["Sent_Neg_Title", "Sent_Neu_Title", "Sent_Pos_Title"]] = test_data_task2["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data_task2["Review_Length"] = train_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x)))
train_data_task2["Word_Count_Review"] = train_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
train_data_task2["Title_Length"] = train_data_task2["Title Cleaned"].apply(lambda x: len(str(x)))
train_data_task2["Word_Count_Title"] = train_data_task2["Title Cleaned"].apply(lambda x: len(str(x).split()))
test_data_task2["Review_Length"] = test_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x)))
test_data_task2["Word_Count_Review"] = test_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
test_data_task2["Title_Length"] = test_data_task2["Title Cleaned"].apply(lambda x: len(str(x)))
test_data_task2["Word_Count_Title"] = test_data_task2["Title Cleaned"].apply(lambda x: len(str(x).split()))
tfidf_review = TfidfVectorizer(ngram_range=(2, 4), max_features=100)
train_review_tfidf = tfidf_review.fit_transform(train_data_task2["Review Text Cleaned"])
test_review_tfidf = tfidf_review.transform(test_data_task2["Review Text Cleaned"])
train_review_tfidf_df = pd.DataFrame(train_review_tfidf.toarray(), columns=[f"review_tfidf_{i}" for i in range(train_review_tfidf.shape[1])])
test_review_tfidf_df = pd.DataFrame(test_review_tfidf.toarray(), columns=[f"review_tfidf_{i}" for i in range(test_review_tfidf.shape[1])])
vader = SentimentIntensityAnalyzer()
def get_sentiment_intensity(text):
sentiment = vader.polarity_scores(text)
return sentiment["compound"]
train_data_task2["Sentiment_Intensity_Review"] = train_data_task2["Review Text Cleaned"].apply(get_sentiment_intensity)
train_data_task2["Sentiment_Intensity_Title"] = train_data_task2["Title Cleaned"].apply(get_sentiment_intensity)
test_data_task2["Sentiment_Intensity_Review"] = test_data_task2["Review Text Cleaned"].apply(get_sentiment_intensity)
test_data_task2["Sentiment_Intensity_Title"] = test_data_task2["Title Cleaned"].apply(get_sentiment_intensity)
def get_emotion_scores_nrclex(text):
emotion = NRCLex(text)
return emotion.affect_frequencies
train_data_task2["Emotion_Scores_Review"] = train_data_task2["Review Text Cleaned"].apply(get_emotion_scores_nrclex)
train_data_task2["Emotion_Scores_Title"] = train_data_task2["Title Cleaned"].apply(get_emotion_scores_nrclex)
test_data_task2["Emotion_Scores_Review"] = test_data_task2["Review Text Cleaned"].apply(get_emotion_scores_nrclex)
test_data_task2["Emotion_Scores_Title"] = test_data_task2["Title Cleaned"].apply(get_emotion_scores_nrclex)
emotions = ["anger", "anticipation", "disgust", "fear", "joy", "sadness", "surprise", "trust"]
def expand_emotion_scores(df, column_prefix):
for emotion in emotions:
df[f"{column_prefix}_{emotion}"] = df[column_prefix].apply(lambda x: x.get(emotion, 0))
return df.drop(columns=[column_prefix])
train_features_2 = train_data_task2.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned"])
test_features_2 = test_data_task2.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned"])
train_features_2_reset = train_features_2.reset_index(drop=True)
test_features_2_reset = test_features_2.reset_index(drop=True)
X_train_task2 = train_features_2_reset
X_test_task2 = test_features_2_reset
X_train_task2 = pd.concat([X_train_task2, train_review_tfidf_df], axis=1)
X_test_task2 = pd.concat([X_test_task2, test_review_tfidf_df], axis=1)
X_train_task2["Sentiment_Intensity_Review"] = train_data_task2["Sentiment_Intensity_Review"]
X_train_task2["Sentiment_Intensity_Title"] = train_data_task2["Sentiment_Intensity_Title"]
X_test_task2["Sentiment_Intensity_Review"] = test_data_task2["Sentiment_Intensity_Review"]
X_test_task2["Sentiment_Intensity_Title"] = test_data_task2["Sentiment_Intensity_Title"]
X_train_task2["Emotion_Scores_Review"] = train_data_task2["Emotion_Scores_Review"]
X_train_task2["Emotion_Scores_Title"] = train_data_task2["Emotion_Scores_Title"]
X_test_task2["Emotion_Scores_Review"] = test_data_task2["Emotion_Scores_Review"]
X_test_task2["Emotion_Scores_Title"] = test_data_task2["Emotion_Scores_Title"]
X_train_task2 = expand_emotion_scores(X_train_task2, "Emotion_Scores_Review")
X_train_task2 = expand_emotion_scores(X_train_task2, "Emotion_Scores_Title")
X_test_task2 = expand_emotion_scores(X_test_task2, "Emotion_Scores_Review")
X_test_task2 = expand_emotion_scores(X_test_task2, "Emotion_Scores_Title")
print("X_train_task2 shape:", X_train_task2.shape)
print("X_test_task2 shape:", X_test_task2.shape)
def get_sentiment(text):
blob = TextBlob(text)
polarity = blob.sentiment.polarity
if polarity < -0.05:
return 1, 0, 0
elif polarity > 0.05:
return 0, 0, 1
else:
return 0, 1, 0
train_data_task2[["Sent_Neg_Review", "Sent_Neu_Review", "Sent_Pos_Review"]] = train_data_task2["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data_task2[["Sent_Neg_Title", "Sent_Neu_Title", "Sent_Pos_Title"]] = train_data_task2["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data_task2[["Sent_Neg_Review", "Sent_Neu_Review", "Sent_Pos_Review"]] = test_data_task2["Review Text Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
test_data_task2[["Sent_Neg_Title", "Sent_Neu_Title", "Sent_Pos_Title"]] = test_data_task2["Title Cleaned"].apply(lambda x: pd.Series(get_sentiment(x)))
train_data_task2["Review_Length"] = train_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x)))
train_data_task2["Word_Count_Review"] = train_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
train_data_task2["Title_Length"] = train_data_task2["Title Cleaned"].apply(lambda x: len(str(x)))
train_data_task2["Word_Count_Title"] = train_data_task2["Title Cleaned"].apply(lambda x: len(str(x).split()))
test_data_task2["Review_Length"] = test_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x)))
test_data_task2["Word_Count_Review"] = test_data_task2["Review Text Cleaned"].apply(lambda x: len(str(x).split()))
test_data_task2["Title_Length"] = test_data_task2["Title Cleaned"].apply(lambda x: len(str(x)))
test_data_task2["Word_Count_Title"] = test_data_task2["Title Cleaned"].apply(lambda x: len(str(x).split()))
tfidf_review = TfidfVectorizer(ngram_range=(2, 4), max_features=100)
train_review_tfidf = tfidf_review.fit_transform(train_data_task2["Review Text Cleaned"])
test_review_tfidf = tfidf_review.transform(test_data_task2["Review Text Cleaned"])
train_review_tfidf_df = pd.DataFrame(train_review_tfidf.toarray(), columns=[f"review_tfidf_{i}" for i in range(train_review_tfidf.shape[1])])
test_review_tfidf_df = pd.DataFrame(test_review_tfidf.toarray(), columns=[f"review_tfidf_{i}" for i in range(test_review_tfidf.shape[1])])
vader = SentimentIntensityAnalyzer()
def get_sentiment_intensity(text):
sentiment = vader.polarity_scores(text)
return sentiment["compound"]
train_data_task2["Sentiment_Intensity_Review"] = train_data_task2["Review Text Cleaned"].apply(get_sentiment_intensity)
train_data_task2["Sentiment_Intensity_Title"] = train_data_task2["Title Cleaned"].apply(get_sentiment_intensity)
test_data_task2["Sentiment_Intensity_Review"] = test_data_task2["Review Text Cleaned"].apply(get_sentiment_intensity)
test_data_task2["Sentiment_Intensity_Title"] = test_data_task2["Title Cleaned"].apply(get_sentiment_intensity)
def get_emotion_scores_nrclex(text):
emotion = NRCLex(text)
return emotion.affect_frequencies
train_data_task2["Emotion_Scores_Review"] = train_data_task2["Review Text Cleaned"].apply(get_emotion_scores_nrclex)
train_data_task2["Emotion_Scores_Title"] = train_data_task2["Title Cleaned"].apply(get_emotion_scores_nrclex)
test_data_task2["Emotion_Scores_Review"] = test_data_task2["Review Text Cleaned"].apply(get_emotion_scores_nrclex)
test_data_task2["Emotion_Scores_Title"] = test_data_task2["Title Cleaned"].apply(get_emotion_scores_nrclex)
emotions = ["anger", "anticipation", "disgust", "fear", "joy", "sadness", "surprise", "trust"]
def expand_emotion_scores(df, column_prefix):
for emotion in emotions:
df[f"{column_prefix}_{emotion}"] = df[column_prefix].apply(lambda x: x.get(emotion, 0))
return df.drop(columns=[column_prefix])
train_features_2 = train_data_task2.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned"])
test_features_2 = test_data_task2.drop(columns=["Title", "Review Text", "Title Cleaned", "Review Text Cleaned"])
train_features_2_reset = train_features_2.reset_index(drop=True)
test_features_2_reset = test_features_2.reset_index(drop=True)
X_train_task2 = train_features_2_reset
X_test_task2 = test_features_2_reset
X_train_task2 = pd.concat([X_train_task2, train_review_tfidf_df], axis=1)
X_test_task2 = pd.concat([X_test_task2, test_review_tfidf_df], axis=1)
X_train_task2["Sentiment_Intensity_Review"] = train_data_task2["Sentiment_Intensity_Review"]
X_train_task2["Sentiment_Intensity_Title"] = train_data_task2["Sentiment_Intensity_Title"]
X_test_task2["Sentiment_Intensity_Review"] = test_data_task2["Sentiment_Intensity_Review"]
X_test_task2["Sentiment_Intensity_Title"] = test_data_task2["Sentiment_Intensity_Title"]
X_train_task2["Emotion_Scores_Review"] = train_data_task2["Emotion_Scores_Review"]
X_train_task2["Emotion_Scores_Title"] = train_data_task2["Emotion_Scores_Title"]
X_test_task2["Emotion_Scores_Review"] = test_data_task2["Emotion_Scores_Review"]
X_test_task2["Emotion_Scores_Title"] = test_data_task2["Emotion_Scores_Title"]
X_train_task2 = expand_emotion_scores(X_train_task2, "Emotion_Scores_Review")
X_train_task2 = expand_emotion_scores(X_train_task2, "Emotion_Scores_Title")
X_test_task2 = expand_emotion_scores(X_test_task2, "Emotion_Scores_Review")
X_test_task2 = expand_emotion_scores(X_test_task2, "Emotion_Scores_Title")
print("X_train_task2 shape:", X_train_task2.shape)
print("X_test_task2 shape:", X_test_task2.shape)Results
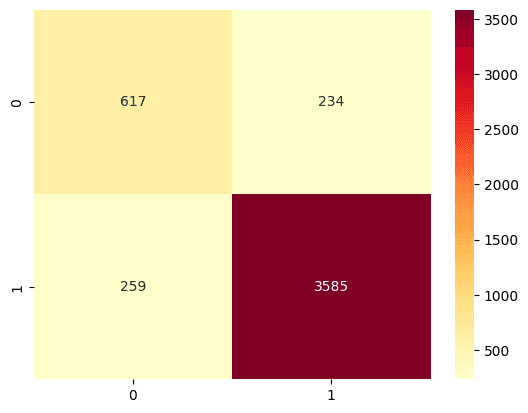
LightGBM for Recommendation Prediction (accuracy: 0.89, weighted F1-score: 0.90)
XGBoost for Rating Prediction (accuracy: 0.60, weighted F1-score: 0.56)
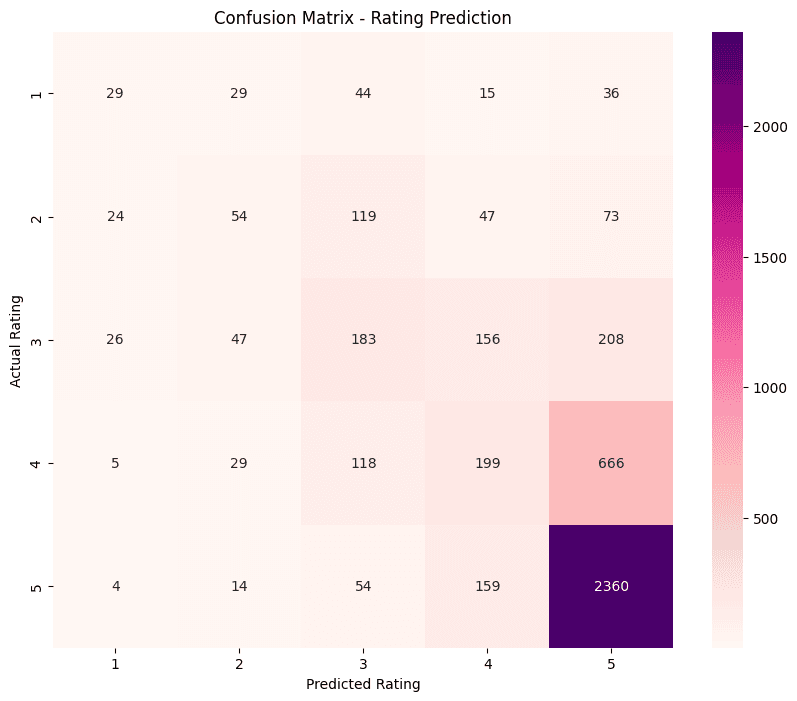
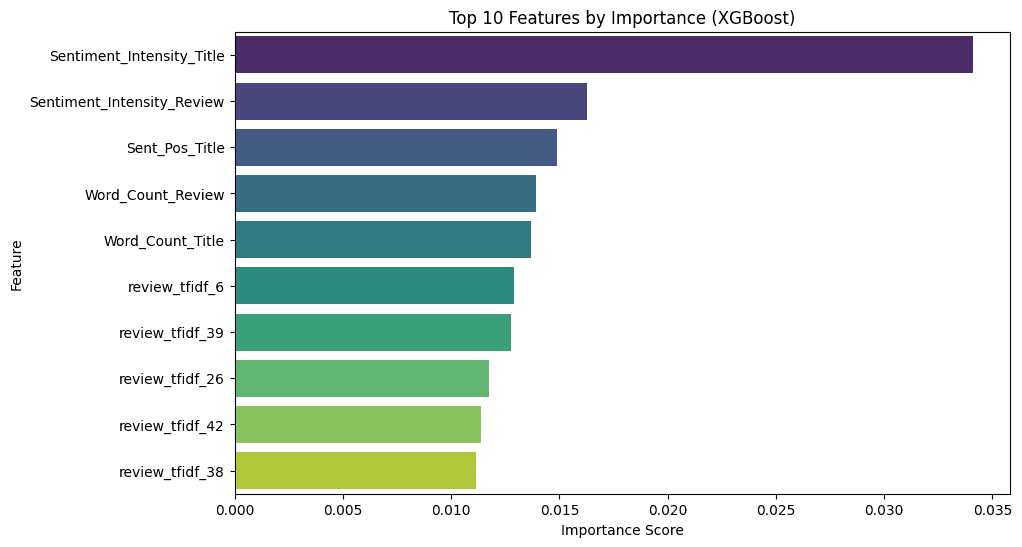
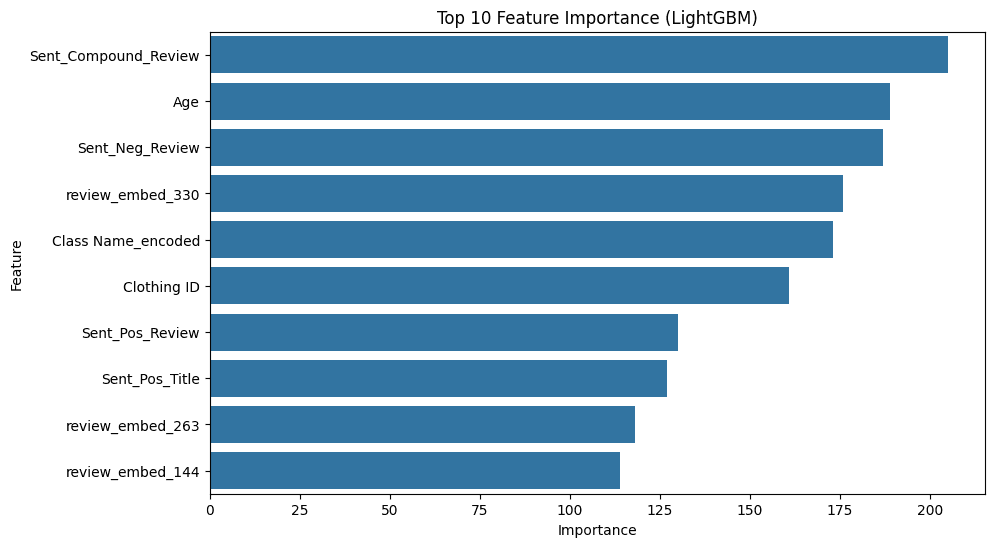
For the recommendation prediction task, sentiment scores (e.g., positive, negative, and compound sentiment) and BERT embeddings of the review text and title are influential features, followed by other demographic and categorical features. This highlights the importance of understanding the emotional tone, semantic meaning, and background of customer reviews. For the star rating prediction task, once again, the sentiment expressed in the review is the most important predictor, alongside specific dimensions of the TF-IDF vectors. This suggests that how a customer feels and views a product is a strong proxy for their recommendation behavior and star rating. Both tasks faced challenges due to class imbalance. For example, in the star rating prediction task, the model performed well for the majority class (5-star ratings) but struggled with minority classes (1-star to 4-star ratings). This is a common issue in real-world datasets, where extreme ratings (very positive or very negative) are easier to detect than moderate or neutral ratings.
Discussions & Implication
The analysis of the LightGBM and XGBoost models for predicting customer recommendations and star ratings provides valuable insights into the strengths and limitations of these approaches in a business setting. First, insights from sentiment analysis can help businesses identify specific pain points or areas of improvement. For instance, negative sentiment in reviews about product quality, fit, or delivery can guide product development and operational changes. Second, accurately predicting customer recommendations and star ratings can help businesses identify satisfied and dissatisfied customers. Specifically, customers who give low ratings or do not recommend a product may be at risk of churn. Addressing their concerns (e.g., through targeted outreach or product improvements) can improve customer retention and loyalty. Furthermore, understanding the factors that drive recommendations and high ratings can inform marketing strategies. For example, businesses can highlight features or aspects of products that are frequently praised in reviews, or they can personalize recommendations based on customer sentiment and preferences. However, the models' poor performance on low ratings and non-recommendations is a significant limitation because failing to identify dissatisfied customers can result in missed opportunities to address issues and improve customer experience.
To unlock the full potential of these models to improve customer satisfaction, drive product improvements, and enhance marketing strategies, businesses can:
Address class imbalance by oversampling minority classes or undersampling majority classes, using class weights during model training, or applying advanced methods like SMOTE (Synthetic Minority Oversampling Technique) to generate synthetic samples for minority classes.
Leverage ordinal classification techniques with models specifically designed for ordinal classification such as ordinal logistic regression or models with ordinal-aware loss functions
Invest in more advanced feature engineering, including domain-specific sentiment analysis and topic modeling, to capture additional nuances in customer reviews while incorporating customer demographics (e.g., age, location, purchase history) to provide additional context for predictions.


